* [WireGuard] fq, ecn, etc with wireguard
@ 2016-08-27 21:03 Dave Taht
2016-08-27 21:33 ` jens
` (2 more replies)
0 siblings, 3 replies; 12+ messages in thread
From: Dave Taht @ 2016-08-27 21:03 UTC (permalink / raw)
To: wireguard
I have been running a set of tinc based vpns for a long time now, and
based on the complexity of the codebase, and some general flakyness
and slowness, I am considering fiddling with wireguard for a
replacement of it. The review of it over on
https://plus.google.com/+gregkroahhartman/posts/NoGTVYbBtiP?hl=3Den was
pretty inspiring.
My principal work is on queueing algorithms (like fq_codel, and cake),
and what I'm working on now is primarily adding these algos to wifi,
but I do need a working vpn, and have longed to improve latency and
loss recovery on vpns for quite some time now.
A) does wireguard handle ecn encapsulation/decapsulation?
https://tools.ietf.org/html/draft-ietf-tsvwg-ecn-encap-guidelines-07
Doing ecn "right" through vpn with a bottleneck router with a fq_codel
enabled qdisc allows for zero induced packet loss and good congestion
control.
B) I see that "noqueue" is the default qdisc for wireguard. What is
the maximum outstanding queue depth held internally? How is it
configured? I imagine it is a strict fifo queue, and that wireguard
bottlenecks on the crypto step and drops on reads... eventually.
Managing the queue length looks to be helpful especially in the
openwrt/lede case.
(we have managed to successfully apply something fq_codel-like within
the mac80211 layer, see various blog entries of mine and the ongoing
work on the make-wifi-fast mailing list)
So managing the inbound queue for wireguard well, to hold induced
latencies down to bare minimums when going from 1Gbit to XMbit, and
it's bottlenecked on wireguard, rather than an external router, is on
my mind. Got a pretty nice hammer in the fq_codel code, not sure why
you have noqueue as the default.
C) One flaw of fq_codel , is that multiplexing multiple outbound flows
over a single connection endpoint degrades that aggregate flow to
codel's behavior, and the vpn "flow" competes evenly with all other
flows. A classic pure aqm solution would be more fair to vpn
encapsulated flows than fq_codel is.
An answer to that would be to expose "fq" properties to the underlying
vpn protocol. For example, being able to specify an endpoint
identifier of 2001:db8:1234::1/118:udp_port would allow for a one to
one mapping for external fq_codel queues to internal vpn queues, and
thus vpn traffic would compete equally with non-vpn traffic at the
router. While this does expose more per flow information, the
corresponding decrease for e2e latency under load, especially for
"sparse" flows, like voip and dns, strikes me as a potential major win
(and one way to use up a bunch of ipv6 addresses in a good cause).
Doing that "right" however probably involves negotiating perfect
forward secrecy for a ton of mostly idle channels (with a separate
seqno base for each), (but I could live with merely having a /123 on
the task)
C1) (does the current codebase work with ipv6?)
D) my end goal would be to somehow replicate the meshy characteristics
of tinc, and choosing good paths through multiple potential
connections, leveraging source specific routing and another layer 3
routing protocol like babel, but I do grok that doing that right would
take a ton more work...
Anyway, I'll go off and read some more docs and code to see if I can
answer a few of these questions myself. I am impressed by what little
I understand so far.
--=20
Dave T=C3=A4ht
Let's go make home routers and wifi faster! With better software!
http://blog.cerowrt.org
^ permalink raw reply [flat|nested] 12+ messages in thread* Re: [WireGuard] fq, ecn, etc with wireguard 2016-08-27 21:03 [WireGuard] fq, ecn, etc with wireguard Dave Taht @ 2016-08-27 21:33 ` jens 2016-08-27 22:03 ` Dave Taht 2016-08-29 17:16 ` Jason A. Donenfeld 2 siblings, 0 replies; 12+ messages in thread From: jens @ 2016-08-27 21:33 UTC (permalink / raw) To: wireguard [-- Attachment #1: Type: text/plain, Size: 3813 bytes --] we have done some tests with wireguard and on top l2tp_v3 and batman-adv this way batman adv handles the routing. on monday we may change from our tinc tunnel to this setup. in test scenarios we got stable 5-600 Mbit on a 1 Gbit cable. Everthing seem prety stable. On 27.08.2016 23:03, Dave Taht wrote: > I have been running a set of tinc based vpns for a long time now, and > based on the complexity of the codebase, and some general flakyness > and slowness, I am considering fiddling with wireguard for a > replacement of it. The review of it over on > https://plus.google.com/+gregkroahhartman/posts/NoGTVYbBtiP?hl=en was > pretty inspiring. > > My principal work is on queueing algorithms (like fq_codel, and cake), > and what I'm working on now is primarily adding these algos to wifi, > but I do need a working vpn, and have longed to improve latency and > loss recovery on vpns for quite some time now. > > A) does wireguard handle ecn encapsulation/decapsulation? > > https://tools.ietf.org/html/draft-ietf-tsvwg-ecn-encap-guidelines-07 > > Doing ecn "right" through vpn with a bottleneck router with a fq_codel > enabled qdisc allows for zero induced packet loss and good congestion > control. > > B) I see that "noqueue" is the default qdisc for wireguard. What is > the maximum outstanding queue depth held internally? How is it > configured? I imagine it is a strict fifo queue, and that wireguard > bottlenecks on the crypto step and drops on reads... eventually. > Managing the queue length looks to be helpful especially in the > openwrt/lede case. > > (we have managed to successfully apply something fq_codel-like within > the mac80211 layer, see various blog entries of mine and the ongoing > work on the make-wifi-fast mailing list) > > So managing the inbound queue for wireguard well, to hold induced > latencies down to bare minimums when going from 1Gbit to XMbit, and > it's bottlenecked on wireguard, rather than an external router, is on > my mind. Got a pretty nice hammer in the fq_codel code, not sure why > you have noqueue as the default. > > C) One flaw of fq_codel , is that multiplexing multiple outbound flows > over a single connection endpoint degrades that aggregate flow to > codel's behavior, and the vpn "flow" competes evenly with all other > flows. A classic pure aqm solution would be more fair to vpn > encapsulated flows than fq_codel is. > > An answer to that would be to expose "fq" properties to the underlying > vpn protocol. For example, being able to specify an endpoint > identifier of 2001:db8:1234::1/118:udp_port would allow for a one to > one mapping for external fq_codel queues to internal vpn queues, and > thus vpn traffic would compete equally with non-vpn traffic at the > router. While this does expose more per flow information, the > corresponding decrease for e2e latency under load, especially for > "sparse" flows, like voip and dns, strikes me as a potential major win > (and one way to use up a bunch of ipv6 addresses in a good cause). > Doing that "right" however probably involves negotiating perfect > forward secrecy for a ton of mostly idle channels (with a separate > seqno base for each), (but I could live with merely having a /123 on > the task) > > C1) (does the current codebase work with ipv6?) > > D) my end goal would be to somehow replicate the meshy characteristics > of tinc, and choosing good paths through multiple potential > connections, leveraging source specific routing and another layer 3 > routing protocol like babel, but I do grok that doing that right would > take a ton more work... > > Anyway, I'll go off and read some more docs and code to see if I can > answer a few of these questions myself. I am impressed by what little > I understand so far. > -- make the world nicer, please use PGP encryption [-- Attachment #2: Type: text/html, Size: 4407 bytes --] ^ permalink raw reply [flat|nested] 12+ messages in thread
* Re: [WireGuard] fq, ecn, etc with wireguard 2016-08-27 21:03 [WireGuard] fq, ecn, etc with wireguard Dave Taht 2016-08-27 21:33 ` jens @ 2016-08-27 22:03 ` Dave Taht 2016-08-29 17:16 ` Jason A. Donenfeld 2 siblings, 0 replies; 12+ messages in thread From: Dave Taht @ 2016-08-27 22:03 UTC (permalink / raw) To: wireguard I cited the wrong ecn draft: https://tools.ietf.org/id/draft-ietf-tsvwg-ecn-tunnel-10.txt Despite the complexity of the draft, basically copying the inner ecn bits to the outer header on encaps, and or-ing ecn bits to inner header (except when 00s) on decaps, seems to be the "right thing", nowadays. On Sat, Aug 27, 2016 at 2:03 PM, Dave Taht <dave.taht@gmail.com> wrote: > I have been running a set of tinc based vpns for a long time now, and > based on the complexity of the codebase, and some general flakyness > and slowness, I am considering fiddling with wireguard for a > replacement of it. The review of it over on > https://plus.google.com/+gregkroahhartman/posts/NoGTVYbBtiP?hl=3Den was > pretty inspiring. > > My principal work is on queueing algorithms (like fq_codel, and cake), > and what I'm working on now is primarily adding these algos to wifi, > but I do need a working vpn, and have longed to improve latency and > loss recovery on vpns for quite some time now. > > A) does wireguard handle ecn encapsulation/decapsulation? > > https://tools.ietf.org/html/draft-ietf-tsvwg-ecn-encap-guidelines-07 > > Doing ecn "right" through vpn with a bottleneck router with a fq_codel > enabled qdisc allows for zero induced packet loss and good congestion > control. > > B) I see that "noqueue" is the default qdisc for wireguard. What is > the maximum outstanding queue depth held internally? How is it > configured? I imagine it is a strict fifo queue, and that wireguard > bottlenecks on the crypto step and drops on reads... eventually. > Managing the queue length looks to be helpful especially in the > openwrt/lede case. > > (we have managed to successfully apply something fq_codel-like within > the mac80211 layer, see various blog entries of mine and the ongoing > work on the make-wifi-fast mailing list) > > So managing the inbound queue for wireguard well, to hold induced > latencies down to bare minimums when going from 1Gbit to XMbit, and > it's bottlenecked on wireguard, rather than an external router, is on > my mind. Got a pretty nice hammer in the fq_codel code, not sure why > you have noqueue as the default. > > C) One flaw of fq_codel , is that multiplexing multiple outbound flows > over a single connection endpoint degrades that aggregate flow to > codel's behavior, and the vpn "flow" competes evenly with all other > flows. A classic pure aqm solution would be more fair to vpn > encapsulated flows than fq_codel is. > > An answer to that would be to expose "fq" properties to the underlying > vpn protocol. For example, being able to specify an endpoint > identifier of 2001:db8:1234::1/118:udp_port would allow for a one to > one mapping for external fq_codel queues to internal vpn queues, and > thus vpn traffic would compete equally with non-vpn traffic at the > router. While this does expose more per flow information, the > corresponding decrease for e2e latency under load, especially for > "sparse" flows, like voip and dns, strikes me as a potential major win > (and one way to use up a bunch of ipv6 addresses in a good cause). > Doing that "right" however probably involves negotiating perfect > forward secrecy for a ton of mostly idle channels (with a separate > seqno base for each), (but I could live with merely having a /123 on > the task) > > C1) (does the current codebase work with ipv6?) > > D) my end goal would be to somehow replicate the meshy characteristics > of tinc, and choosing good paths through multiple potential > connections, leveraging source specific routing and another layer 3 > routing protocol like babel, but I do grok that doing that right would > take a ton more work... > > Anyway, I'll go off and read some more docs and code to see if I can > answer a few of these questions myself. I am impressed by what little > I understand so far. > > -- > Dave T=C3=A4ht > Let's go make home routers and wifi faster! With better software! > http://blog.cerowrt.org --=20 Dave T=C3=A4ht Let's go make home routers and wifi faster! With better software! http://blog.cerowrt.org ^ permalink raw reply [flat|nested] 12+ messages in thread
* Re: [WireGuard] fq, ecn, etc with wireguard 2016-08-27 21:03 [WireGuard] fq, ecn, etc with wireguard Dave Taht 2016-08-27 21:33 ` jens 2016-08-27 22:03 ` Dave Taht @ 2016-08-29 17:16 ` Jason A. Donenfeld 2016-08-29 19:23 ` Jason A. Donenfeld 2016-08-30 0:24 ` Dave Taht 2 siblings, 2 replies; 12+ messages in thread From: Jason A. Donenfeld @ 2016-08-29 17:16 UTC (permalink / raw) To: Dave Taht; +Cc: WireGuard mailing list Hey Dave, You're exactly the sort of person I've been hoping would appear during the last several months. Indeed there's a lot of interesting queueing things happening with WireGuard. I'll detail them inline below. > I have been running a set of tinc based vpns for a long time now, and > based on the complexity of the codebase, and some general flakyness > and slowness, I am considering fiddling with wireguard for a > replacement of it. The review of it over on > https://plus.google.com/+gregkroahhartman/posts/NoGTVYbBtiP?hl=en was > pretty inspiring. Indeed this seems to be a very common use case of WireGuard -- replacing complex userspace things with something fast and simple. You've come to the right place. :-P > My principal work is on queueing algorithms (like fq_codel, and cake), > and what I'm working on now is primarily adding these algos to wifi, > but I do need a working vpn, and have longed to improve latency and > loss recovery on vpns for quite some time now. Great. > > A) does wireguard handle ecn encapsulation/decapsulation? > > https://tools.ietf.org/html/draft-ietf-tsvwg-ecn-encap-guidelines-07 > > Doing ecn "right" through vpn with a bottleneck router with a fq_codel > enabled qdisc allows for zero induced packet loss and good congestion > control. At the moment I don't do anything special with DSCP or ECN. I set a high priority DSCP for the handshake messages, but for the actual transport packets, I leave it at zero: https://git.zx2c4.com/WireGuard/tree/src/send.c#n137 This has been a TODO item for quite some time; it's on wireguard.io/roadmap too. The reason I've left it at zero, thus far, is that I didn't want to infoleak anything about the underlying data. Is there a case to be made, however, that ECN doesn't leak data like DSCP does, and so I'd be okay just copying those top bits? I'll read the IETF draft you sent and see if I can come up with something. It does have an important utility; you're right. > B) I see that "noqueue" is the default qdisc for wireguard. What is > the maximum outstanding queue depth held internally? How is it > configured? I imagine it is a strict fifo queue, and that wireguard > bottlenecks on the crypto step and drops on reads... eventually. > Managing the queue length looks to be helpful especially in the > openwrt/lede case. > > (we have managed to successfully apply something fq_codel-like within > the mac80211 layer, see various blog entries of mine and the ongoing > work on the make-wifi-fast mailing list) > > So managing the inbound queue for wireguard well, to hold induced > latencies down to bare minimums when going from 1Gbit to XMbit, and > it's bottlenecked on wireguard, rather than an external router, is on > my mind. Got a pretty nice hammer in the fq_codel code, not sure why > you have noqueue as the default. There are a couple reasons. Originally I used multiqueue and had a separate subqueue for each peer. I then abused starting and stopping these subqueues as the various peers negotiated handshakes. This worked, but it was quite limiting for a number of reasons, leading me to ultimately switch to noqueue. Using noqueue gives me a couple benefits. First, packet transmission calls my xmit function directly, which means I can trivially check for routing loops using dev_recursion_level(). Second, it allows me to return things like `-ENOKEY` from the xmit function, which gets directly passed up to userspace, giving more interesting error messages than ICMP handles (though I also support ICMP). But the main reason is because it fits the current queuing design of WireGuard. I'll explain: A WireGuard device has multiple peers. Either there's an active session for a peer, in which case the packet can be encrypted and sent, or there isn't, in which case it's queued up until a session is established. If a peer doesn't have a session, after queuing up that packet, the session handshake occurs, and immediately following, the queue is released and the packet is sent. This has the effect of making WireGuard appear "stateless" to userspace. The administrator set up all the peer details, and then typed `ping peer`, and then it just worked. Where did the connection happen? That's what happens behind scenes in WireGuard. So each peer has its own queue. I limit each queue to 1024 packets, somewhat arbitrarily. As the queue exceeds 1024, the oldest packets are dropped first. There's another hitch: Linux supports "super packets" for GSO. Essentially, the kernel will hand off a massive TCP packet -- 65k -- to the device driver, if requested, expecting the device driver to then segment this into MTU-sized bites. This was designed for hardware that has built-in TCP segmentation and such. I found it was very performant to do the same with WireGuard. The reason is that everytime a final encrypted packet is transmitted, it has to traverse the big complicated Linux networking stack. In order to reduce cache misses, I prefer to transmit a bunch of packets at once. Please read this LKML post where I detail this a bit more (Ctrl+F for "It makes use of a few tricks"), and then return to this email: http://lkml.iu.edu/hypermail/linux/kernel/1606.3/02833.html The next thing is that I support parallel encryption, which means encrypting these bundles of packets is asynchronous. All these requirements would lead you to think that this is all super complicated and horrible, but I actually managed to put this together in a decently simple way. There's the queuing algorithm all together: https://git.zx2c4.com/WireGuard/tree/src/device.c#n101 1. user sends a packet. xmit() in device.c is called. 2. look up to which peer we're sending this packet. 3. if we have >1024 packets in that peer's queue, remove the oldest ones. 4. segment the super packet into normal MTU-sized packets, and queue those up. note that this may allow the queue to temporarily exceed 1024 packets, which is fine. 5. try to encrypt&send the entire queue. There's what step 5 looks like, found in packet_send_queue() in send.c: https://git.zx2c4.com/WireGuard/tree/src/send.c#n159 1. immediately empty the entire queue, putting it into a local temp queue. 2. if the queue is empty, return. if the queue only has one packet that's less than or equal to 256 bytes, don't parallelize it. 3. for each packet in the queue, send it off to the asynchronous encryption a. if that returns '-ENOKEY', it means we don't have a valid session, so we should initiate one, and then do (b) too. b. if that returns '-ENOKEY' or '-EBUSY' (workqueue is at kernel limit), we put that packet and all the ones after it from the local queue back into the peer's queue. c. if we fail for any other reason, we drop that packet, and then keep processing the rest of the queue. 4. we tell userspace "ok! sent!" 5. when the packets that were successfully submitted finish encrypting (asynchronously), we transmit the encrypted packets in a tight loop to reduce cache misses in the networking stack. That's it! It's pretty basic. I do wonder if this has some problems, and if you have some suggestions on how to improve it, or what to replace it with. I'm open to all suggestions here. One thing, for example, that I haven't yet worked out is better scheduling for submitting packets to different threads for encryption. Right now I just evenly distribute them, one by one, and then wait until they're finished. Clearly better performance could be achieved by chunking them somehow. > C) One flaw of fq_codel , is that multiplexing multiple outbound flows > over a single connection endpoint degrades that aggregate flow to > codel's behavior, and the vpn "flow" competes evenly with all other > flows. A classic pure aqm solution would be more fair to vpn > encapsulated flows than fq_codel is. > > An answer to that would be to expose "fq" properties to the underlying > vpn protocol. For example, being able to specify an endpoint > identifier of 2001:db8:1234::1/118:udp_port would allow for a one to > one mapping for external fq_codel queues to internal vpn queues, and > thus vpn traffic would compete equally with non-vpn traffic at the > router. While this does expose more per flow information, the > corresponding decrease for e2e latency under load, especially for > "sparse" flows, like voip and dns, strikes me as a potential major win > (and one way to use up a bunch of ipv6 addresses in a good cause). > Doing that "right" however probably involves negotiating perfect > forward secrecy for a ton of mostly idle channels (with a separate > seqno base for each), (but I could live with merely having a /123 on > the task) Do you mean to suggest that there be a separate wireguard session for each 4-tuple? > C1) (does the current codebase work with ipv6?) Yes, very well, out of the box, from day 1. You can do v6-in-v6, v4-in-v4, v4-in-v6, and v6-in-v4. > D) my end goal would be to somehow replicate the meshy characteristics > of tinc, and choosing good paths through multiple potential > connections, leveraging source specific routing and another layer 3 > routing protocol like babel, but I do grok that doing that right would > take a ton more work... That'd be great. I'm trying to find a chance to sit down with the fella behind Babel one of these days. I'd love to get these working well together. > Anyway, I'll go off and read some more docs and code to see if I can > answer a few of these questions myself. I am impressed by what little > I understand so far. Great! Let me know what you find. Feel free to find me in IRC (zx2c4 in #wireguard on freenode) if you'd like to chat about this all in realtime. Regards, Jason ^ permalink raw reply [flat|nested] 12+ messages in thread
* Re: [WireGuard] fq, ecn, etc with wireguard 2016-08-29 17:16 ` Jason A. Donenfeld @ 2016-08-29 19:23 ` Jason A. Donenfeld 2016-08-29 19:50 ` Dave Taht 2016-08-29 20:15 ` Dave Taht 2016-08-30 0:24 ` Dave Taht 1 sibling, 2 replies; 12+ messages in thread From: Jason A. Donenfeld @ 2016-08-29 19:23 UTC (permalink / raw) To: Dave Taht; +Cc: WireGuard mailing list Hi again, So I implemented a first stab of this, which I intend to refine with your feedback: https://git.zx2c4.com/WireGuard/commit/?id=a2dfc902e942cce8d5da4a42d6aa384413e7fc81 On the way out, the ECN is set to: outgoing_skb->tos = encap_ecn(0, inner_skb->tos); where encap_ecn is defined as: u8 encap_ecn(u8 outer, u8 inner) { outer &= ~INET_ECN_MASK; outer |= !INET_ECN_is_ce(inner) ? (inner & INET_ECN_MASK) : INET_ECN_ECT_0; return outer; } Since outer goes in as 0, this function can be reduced to simply: outgoing_skb->tos = !INET_ECN_is_ce(inner_skb->tos) ? (inner_skb->tos & INET_ECN_MASK) : INET_ECN_ECT_0; QUESTION A: is 0 a good value to use here as outer? Or, in fact, should I use the tos value that comes from the routing table for the outer route? On the way in, the ECN is set to: if (INET_ECN_is_ce(outer_skb->tos)) IP_ECN_set_ce(inner_skb->tos) I do NOT compute the following: if (INET_ECN_is_not_ect(inner)) { switch (outer & INET_ECN_MASK) { case INET_ECN_NOT_ECT: return EVERYTHING_IS_OKAY; case INET_ECN_ECT_0: case INET_ECN_ECT_1: return BROKEN_SO_LOG_PACKET; case INET_ECN_CE: return BROKEN_SO_DROP_PACKET; } } QUESTION B: is it okay that I do not compute the above checks? Or is this potentially very problematic? I await your answer on questions A and B. Thanks, Jason ^ permalink raw reply [flat|nested] 12+ messages in thread
* Re: [WireGuard] fq, ecn, etc with wireguard 2016-08-29 19:23 ` Jason A. Donenfeld @ 2016-08-29 19:50 ` Dave Taht 2016-08-29 20:15 ` Dave Taht 1 sibling, 0 replies; 12+ messages in thread From: Dave Taht @ 2016-08-29 19:50 UTC (permalink / raw) To: Jason A. Donenfeld; +Cc: WireGuard mailing list Nice to see you so quickly being productive. I am still constructing a reply to your previous message. Rather than try to expand your macros, my mental model on encode is if(inner_dscp & 3) outer_dscp = (outer_dscp & 3) | (inner_dscp & 3); decode is different. A bad actor could, for example, flip the outer ecn bits from ect(1) to ect(0) (which have different meanings in the l4s effort in the ietf), or set the outer to CE (one evil ISP did this until the worldwide test by apple last year for ecn capability got them to fix it), when the inner is not ECN capable at all. if(itos = inner_dscp & 3) if (otos = outer_dscp & 3) if(otos == 3) itos = itos | 3; I see you are using the cb to temporarily store these bits. If we end up sneaking fq_codel into there, you'll also need space for a timestamp and another field..... I didn't even know ip_tunnel_get_dsfield() even existed! ^ permalink raw reply [flat|nested] 12+ messages in thread
* Re: [WireGuard] fq, ecn, etc with wireguard 2016-08-29 19:23 ` Jason A. Donenfeld 2016-08-29 19:50 ` Dave Taht @ 2016-08-29 20:15 ` Dave Taht 2016-08-29 21:00 ` Jason A. Donenfeld 1 sibling, 1 reply; 12+ messages in thread From: Dave Taht @ 2016-08-29 20:15 UTC (permalink / raw) To: Jason A. Donenfeld; +Cc: WireGuard mailing list To try and answer your actual questions... On Mon, Aug 29, 2016 at 12:23 PM, Jason A. Donenfeld <Jason@zx2c4.com> wrot= e: > Hi again, > > So I implemented a first stab of this, which I intend to refine with > your feedback: > > https://git.zx2c4.com/WireGuard/commit/?id=3Da2dfc902e942cce8d5da4a42= d6aa384413e7fc81 > > > On the way out, the ECN is set to: > > outgoing_skb->tos =3D encap_ecn(0, inner_skb->tos); > > where encap_ecn is defined as: > > u8 encap_ecn(u8 outer, u8 inner) > { > outer &=3D ~INET_ECN_MASK; > outer |=3D !INET_ECN_is_ce(inner) ? (inner & INET_ECN_MASK) : > INET_ECN_ECT_0; > return outer; > } > > Since outer goes in as 0, this function can be reduced to simply: > > outgoing_skb->tos =3D !INET_ECN_is_ce(inner_skb->tos) ? (inner_skb->tos > & INET_ECN_MASK) : INET_ECN_ECT_0; > > QUESTION A: is 0 a good value to use here as outer? Or, in fact, > should I use the tos value that comes from the routing table for the > outer route? The outer routing table is read for where stuff comes in in the first place from the packet to make the routing decision. As in general dscp values are not preserved end to end and can cause re-ordering when they are, it's best to use your own dscp value consistently for the outer header and not vary it within the vpn flow based on the inner header. There is a keyword in the ip command (inherit) that can be applied to switch on or off these behaviors. Short answer is - stick with 0. > > On the way in, the ECN is set to: > > if (INET_ECN_is_ce(outer_skb->tos)) > IP_ECN_set_ce(inner_skb->tos) This is not correct. (I think my definition of in and out are different) if (INET_ECN_is_ce(outer_skb->tos) && inner_skb->tos & 3 !=3D 0) // sorry don't have the macro in my head IP_ECN_set_ce(inner_skb->tos) > > I do NOT compute the following: > > if (INET_ECN_is_not_ect(inner)) { > switch (outer & INET_ECN_MASK) { > case INET_ECN_NOT_ECT: > return EVERYTHING_IS_OKAY; > case INET_ECN_ECT_0: > case INET_ECN_ECT_1: > return BROKEN_SO_LOG_PACKET; > case INET_ECN_CE: > return BROKEN_SO_DROP_PACKET; > } > } > > QUESTION B: is it okay that I do not compute the above checks? Or is > this potentially very problematic? > > > I await your answer on questions A and B. > > Thanks, > Jason --=20 Dave T=C3=A4ht Let's go make home routers and wifi faster! With better software! http://blog.cerowrt.org ^ permalink raw reply [flat|nested] 12+ messages in thread
* Re: [WireGuard] fq, ecn, etc with wireguard 2016-08-29 20:15 ` Dave Taht @ 2016-08-29 21:00 ` Jason A. Donenfeld 2016-08-29 21:11 ` Dave Taht 2016-08-29 23:24 ` Dave Taht 0 siblings, 2 replies; 12+ messages in thread From: Jason A. Donenfeld @ 2016-08-29 21:00 UTC (permalink / raw) To: Dave Taht; +Cc: WireGuard mailing list > Nice to see you so quickly being productive. I am still constructing a > reply to your previous message. Awaiting it's arrival :) > In re-reading over your message, I think not dropping the packet when > there is an outer CE marking and no ecn enabling in in the inner > packet is probably the right thing, by Postel's law, if not, by the > RFCs. Vxlan, geneveve, ipip, and sit all log & drop for the last condition. Xfrm (IPsec) does not. The RFCs seem to indicate that it should be dropped though. Check out the function here, used by vxlan, geneveve, ipip, and sit: (A) https://git.zx2c4.com/linux/tree/include/net/inet_ecn.h#n166 IPsec uses this much shorter function here, on which I've modeled mine: (B) https://git.zx2c4.com/linux/tree/net/ipv4/xfrm4_mode_tunnel.c#n18 > Are you in a position to test this? (pie and fq_codel both support > ecn. My go-to script for testing stuff like this locally are the > sqm-scripts, or cake, and enabling ecn in /etc/sysctl.conf > > https://www.bufferbloat.net/projects/codel/wiki/CakeTechnical/ > > tc qdisc add dev eth0 root cake bandwidth 10mbit # or ratelimit with > the sqm-scripts and fq_codel or pie with ecn enabled > > and enabling ecn in /etc/sysctl.conf > > sysctl -w net.ipv4.tcp_ecn=1 > > And aggh, there's another part of your message I missed, and I haven't > answered the first one yet. Cool. I didn't even have the qdisc functions compiled into my kernel! But anyway I went ahead and compiled your module and modified iproute2, and then modified src/tests/netns.sh as follows: diff --git a/src/tests/netns.sh b/src/tests/netns.sh index 1c638d4..294dea6 100755 --- a/src/tests/netns.sh +++ b/src/tests/netns.sh @@ -58,6 +58,11 @@ ip netns del $netns2 2>/dev/null || true pp ip netns add $netns0 pp ip netns add $netns1 pp ip netns add $netns2 +n0 sysctl -w net.ipv4.tcp_ecn=1 +n1 sysctl -w net.ipv4.tcp_ecn=1 +n2 sysctl -w net.ipv4.tcp_ecn=1 +n0 /home/zx2c4/iproute2-cake/tc/tc qdisc add dev lo root cake bandwidth 10mbit + ip0 link set up dev lo ip0 link add dev wg0 type wireguard After that, I ran it and then looked at tcpdump at the lo device that connects the two namespaces (see netns.sh for an explanation of how this works). I saw lots of things like this: 22:41:40.386446 IP (tos 0x0, ttl 64, id 56003, offset 0, flags [none], proto UDP (17), length 121) 127.0.0.1.2 > 127.0.0.1.1: UDP, length 93 22:41:40.386552 IP (tos 0x2,ECT(0), ttl 64, id 56005, offset 0, flags [none], proto UDP (17), length 1480) 127.0.0.1.1 > 127.0.0.1.2: UDP, length 1452 22:41:40.387776 IP (tos 0x2,ECT(0), ttl 64, id 56006, offset 0, flags [none], proto UDP (17), length 1480) 127.0.0.1.1 > 127.0.0.1.2: UDP, length 1452 These are the outer encrypted UDP packets. I assume that the decrypted data inside is an ACK followed by two data packets. ECT is marked for the data packets, then. Does this mean it works? How precisely do I test correct behavior? > Short answer is - stick with 0. Okay. In that case, when outgoing, the ECN calculation will always be: outgoing_skb->tos = !INET_ECN_is_ce(inner_skb->tos) ? (inner_skb->tos & INET_ECN_MASK) : INET_ECN_ECT_0; Can you verify this is correct? > This is not correct. (I think my definition of in and out are different) > > if (INET_ECN_is_ce(outer_skb->tos) && inner_skb->tos & 3 != 0) // > sorry don't have the macro in my head See (A) and (B) above. They seem to do what I'm doing. ^ permalink raw reply [flat|nested] 12+ messages in thread
* Re: [WireGuard] fq, ecn, etc with wireguard 2016-08-29 21:00 ` Jason A. Donenfeld @ 2016-08-29 21:11 ` Dave Taht 2016-08-29 23:24 ` Dave Taht 1 sibling, 0 replies; 12+ messages in thread From: Dave Taht @ 2016-08-29 21:11 UTC (permalink / raw) To: Jason A. Donenfeld; +Cc: WireGuard mailing list well, you should see ect(3) if you pound the network interface. Things like tcp small queues get in the way so you won't see it with a simple single flow test against cake/codel/etc. something like 4 netperfs will do it. Since you are so fast at getting code running, I think you'll like flent as a test tool. It's pretty easy to install: sudo apt-get install python-matplotlib python-qt4 netperf fping # some distros don't include netperf tho # you only need netperf's netserver running on the clients git clone https://github.com/tohojo/flent.git cd flent; sudo make install netserver -N # wherever you have targets It has a zillion tests, lets you plot the results, over time, etc, etc. The rrul test, in particular, would be a good stress test of your code. You can see usage of flent (formerly known as netperf-wrapper) all over the web now.... example test script (with a title of what I'm testing now) #!/bin/sh for i in 1 2 4 8 12 16 24; do flent -t "unencrypted-ht40-$i-flows-osx-ether" -H 192.168.1.201 -l 30 --test-parameter=upload_streams=$i tcp_nup flent -t "unencrypted-ht40-$i-flows-osx-ether" -H 192.168.1.201 -l 30 --test-parameter=download_streams=$i tcp_ndown done flent -t "unencrypted-ht40-$i-flows-osx-ether" -H 192.168.1.201 -l 30 rrul_be flent -t "unencrypted-ht40-$i-flows-osx-ether" -H 192.168.1.201 -l 30 rrul flent-gui *.gz # Anyway, I'll join you in irc to look over what you doing..... ^ permalink raw reply [flat|nested] 12+ messages in thread
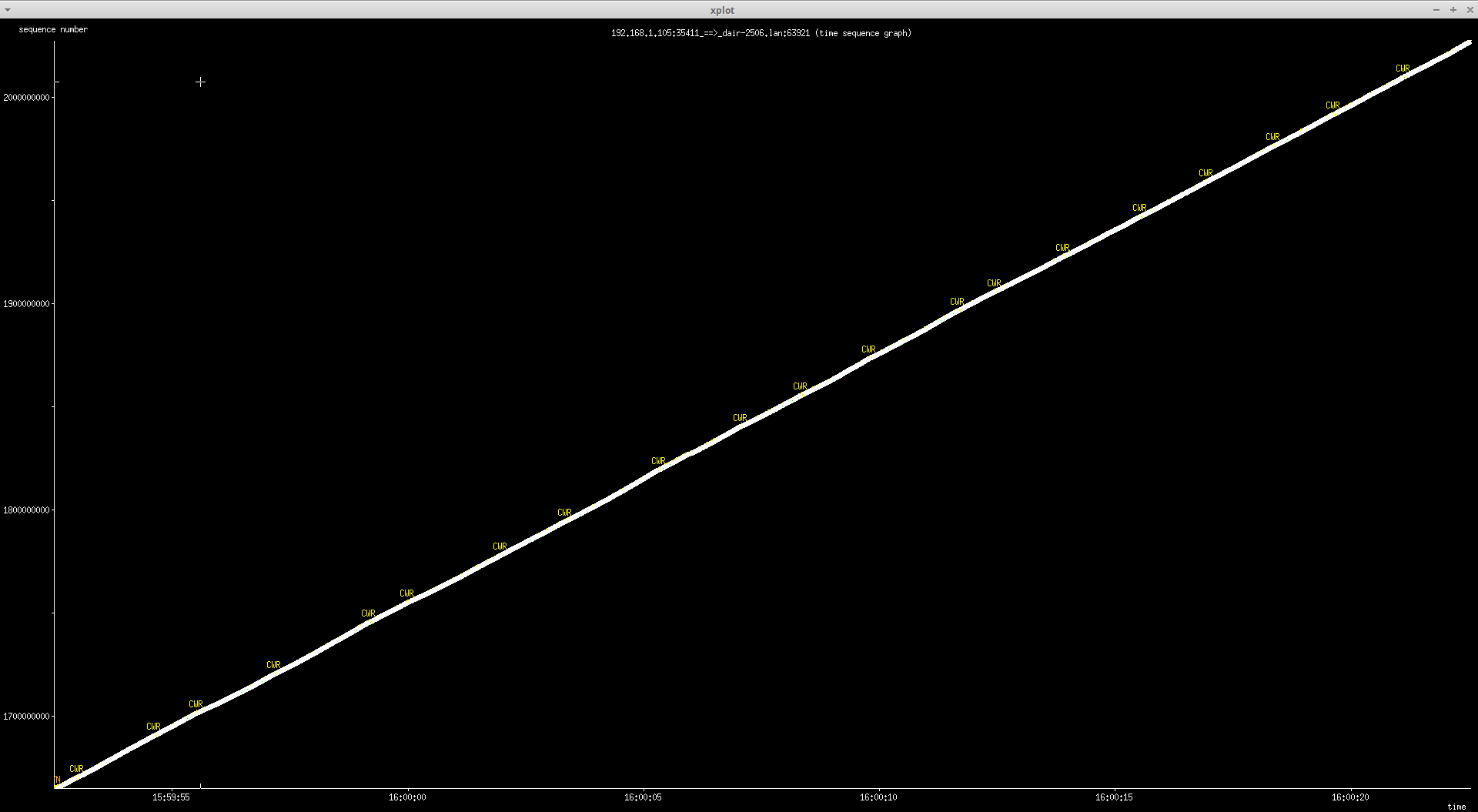
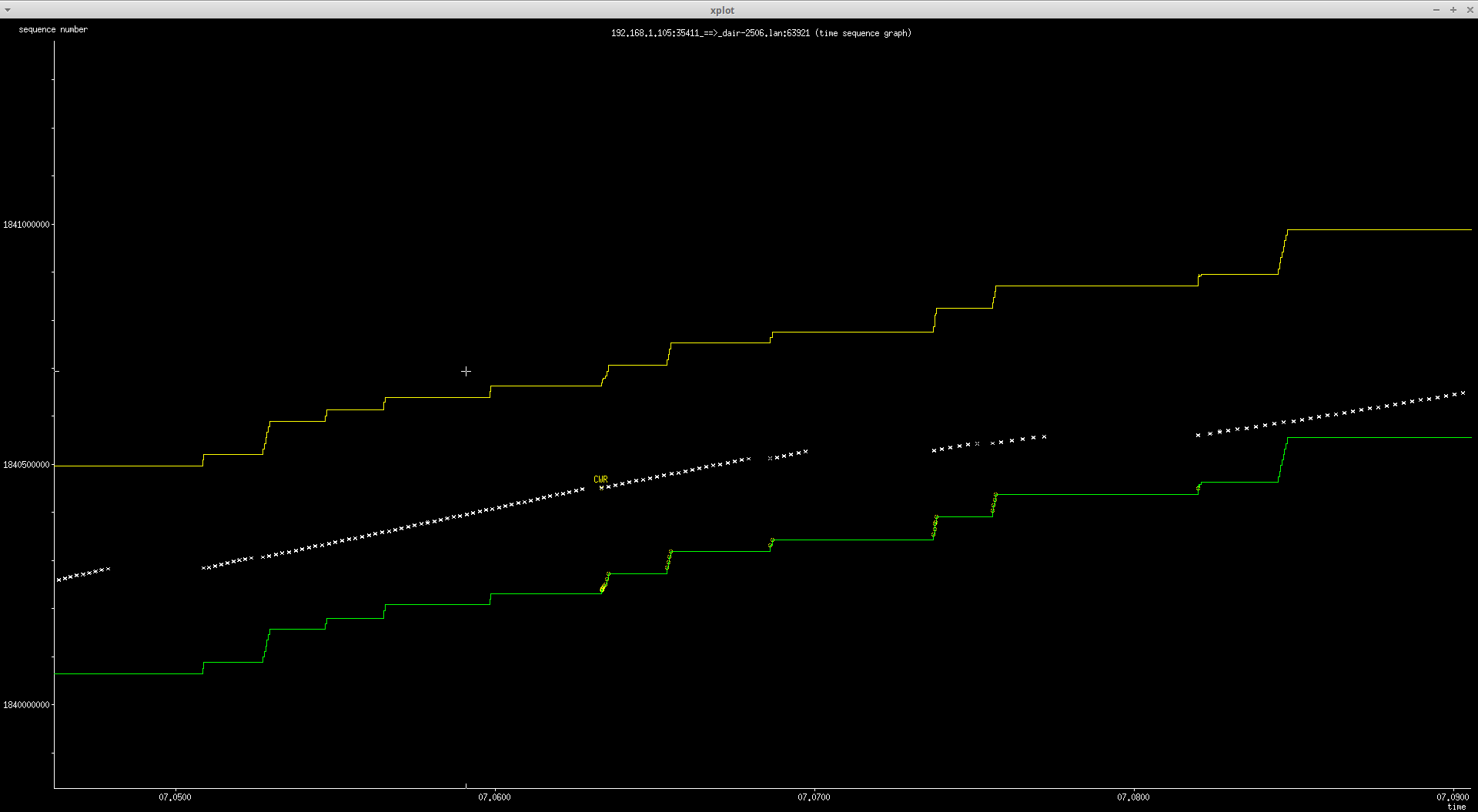
* Re: [WireGuard] fq, ecn, etc with wireguard 2016-08-29 21:00 ` Jason A. Donenfeld 2016-08-29 21:11 ` Dave Taht @ 2016-08-29 23:24 ` Dave Taht 2016-08-29 23:57 ` Jason A. Donenfeld 1 sibling, 1 reply; 12+ messages in thread From: Dave Taht @ 2016-08-29 23:24 UTC (permalink / raw) To: Jason A. Donenfeld; +Cc: WireGuard mailing list On Mon, Aug 29, 2016 at 2:00 PM, Jason A. Donenfeld <Jason@zx2c4.com> wrote= : >> Nice to see you so quickly being productive. I am still constructing a >> reply to your previous message. > > Awaiting it's arrival :) > >> In re-reading over your message, I think not dropping the packet when >> there is an outer CE marking and no ecn enabling in in the inner >> packet is probably the right thing, by Postel's law, if not, by the >> RFCs. > > Vxlan, geneveve, ipip, and sit all log & drop for the last condition. > Xfrm (IPsec) does not. > > The RFCs seem to indicate that it should be dropped though. Check out > the function here, used by vxlan, geneveve, ipip, and sit: > > (A) https://git.zx2c4.com/linux/tree/include/net/inet_ecn.h#n166 > > IPsec uses this much shorter function here, on which I've modeled mine: > > (B) https://git.zx2c4.com/linux/tree/net/ipv4/xfrm4_mode_tunnel.c#n18 Then by all means follow the existing latest code. Postel is long dead, and the internet is a far more hostile place. >> Are you in a position to test this? (pie and fq_codel both support >> ecn. My go-to script for testing stuff like this locally are the >> sqm-scripts, or cake, and enabling ecn in /etc/sysctl.conf >> >> https://www.bufferbloat.net/projects/codel/wiki/CakeTechnical/ >> >> tc qdisc add dev eth0 root cake bandwidth 10mbit # or ratelimit with >> the sqm-scripts and fq_codel or pie with ecn enabled >> >> and enabling ecn in /etc/sysctl.conf >> >> sysctl -w net.ipv4.tcp_ecn=3D1 >> >> And aggh, there's another part of your message I missed, and I haven't >> answered the first one yet. > > Cool. I didn't even have the qdisc functions compiled into my kernel! But > anyway I went ahead and compiled your module and modified iproute2, and t= hen > modified src/tests/netns.sh as follows: > > diff --git a/src/tests/netns.sh b/src/tests/netns.sh > index 1c638d4..294dea6 100755 > --- a/src/tests/netns.sh > +++ b/src/tests/netns.sh > @@ -58,6 +58,11 @@ ip netns del $netns2 2>/dev/null || true > pp ip netns add $netns0 > pp ip netns add $netns1 > pp ip netns add $netns2 > +n0 sysctl -w net.ipv4.tcp_ecn=3D1 > +n1 sysctl -w net.ipv4.tcp_ecn=3D1 > +n2 sysctl -w net.ipv4.tcp_ecn=3D1 > +n0 /home/zx2c4/iproute2-cake/tc/tc qdisc add dev lo root cake > bandwidth 10mbit > + > ip0 link set up dev lo > > ip0 link add dev wg0 type wireguard so did cake manage to successfully ratelimit the output to 10Mbit's in this configuration? cake's stats also show marks and drops. (tc -s qdisc show dev lo) > After that, I ran it and then looked at tcpdump at the lo device that con= nects > the two namespaces (see netns.sh for an explanation of how this works). I= saw > lots of things like this: > > 22:41:40.386446 IP (tos 0x0, ttl 64, id 56003, offset 0, flags [none], > proto UDP (17), length 121) > 127.0.0.1.2 > 127.0.0.1.1: UDP, length 93 acks do not get ECN marks. (I note that mosh is also ecn enabled, last I looked) > 22:41:40.386552 IP (tos 0x2,ECT(0), ttl 64, id 56005, offset 0, flags > [none], proto UDP (17), length 1480) > 127.0.0.1.1 > 127.0.0.1.2: UDP, length 1452 > 22:41:40.387776 IP (tos 0x2,ECT(0), ttl 64, id 56006, offset 0, flags > [none], proto UDP (17), length 1480) This shows the marking making it to the outer header. But you should see 0x3 whenever the qdisc engages it. > 127.0.0.1.1 > 127.0.0.1.2: UDP, length 1452 > > These are the outer encrypted UDP packets. I assume that the decrypted da= ta > inside is an ACK followed by two data packets. ECT is marked for the data > packets, then. > > Does this mean it works? How precisely do I test correct behavior? I am a big fan of flent to generate tests with, and tcptrace -G on the capture of the decrypted interface and looking at the output via xplot.org (not xplot). Looking at the resulting capture on one end, you will see the CE going out, on the other you will see just the CWR and little dots showing the acks acknowledging the CE has been heard and acted upon. example of the latter: http://www.taht.net/~d/typical_ecn_response.png http://www.taht.net/~d/typica_ecn_response_closeupt.png Don't have a pic of the former handy. A *really good intro* to tcptrace an xplot are in apple's presentation on ecn here, starting 16 (or was it 24?) minutes in: https://developer.apple.com/videos/play/wwdc2015/719/ (without a mac, you can just download the video) >> Short answer is - stick with 0. > > Okay. In that case, when outgoing, the ECN calculation will always be: > > outgoing_skb->tos =3D !INET_ECN_is_ce(inner_skb->tos) ? (inner_skb->tos > & INET_ECN_MASK) : INET_ECN_ECT_0; > > Can you verify this is correct? > >> This is not correct. (I think my definition of in and out are different) >> >> if (INET_ECN_is_ce(outer_skb->tos) && inner_skb->tos & 3 !=3D 0) // >> sorry don't have the macro in my head > > See (A) and (B) above. They seem to do what I'm doing. I will. I got very busy today getting a "final" version of the fq_codel code for ath9k wifi tested. It's lovely. :) If you are into openwrt, we've got builds available at: https://lists.bufferbloat.net/pipermail/make-wifi-fast/2016-August/000940.h= tml and patches due out tomorrow. It would be great fun to also start fiddling with wireguard with this new stuff. I think the right thing - now that you've found it - is to ape what the newer protocols do... (and someone shoul fix linux ipsec) --=20 Dave T=C3=A4ht Let's go make home routers and wifi faster! With better software! http://blog.cerowrt.org ^ permalink raw reply [flat|nested] 12+ messages in thread
* Re: [WireGuard] fq, ecn, etc with wireguard 2016-08-29 23:24 ` Dave Taht @ 2016-08-29 23:57 ` Jason A. Donenfeld 0 siblings, 0 replies; 12+ messages in thread From: Jason A. Donenfeld @ 2016-08-29 23:57 UTC (permalink / raw) To: Dave Taht; +Cc: WireGuard mailing list > well, you should see ect(3) if you pound the network interface. Things > like tcp small queues get in the way so you won't see it with a simple > single flow test against cake/codel/etc. > > something like 4 netperfs will do it. It works! 01:40:57.962131 IP (tos 0x3,CE, ttl 64, id 51647, offset 0, flags [none], proto UDP (17), length 1480) I made this happen by giving `-P 50 -N -w 500M ` to iperf3. > sudo apt-get install python-matplotlib python-qt4 netperf fping # some > git clone https://github.com/tohojo/flent.git > cd flent; sudo make install > flent-gui *.gz > I am a big fan of flent to generate tests with, and tcptrace -G on the > capture of the decrypted interface and looking at the output via > xplot.org (not xplot). Looking at the resulting capture on one end, > you will see the CE going out, on the other you will see just the CWR > and little dots showing the acks acknowledging the CE has been heard > and acted upon. Excellent, thanks for the suggestions on testing tools. I've been using iperf3 nearly exclusively, and indeed it seems like netperf and others are substantially more powerful. I've also got a directory of horrible .c programs generating packets for stress testing printing out text for me to pop into Mathematica... Clearly my homebrewed rig isn't going to be useful for much longer. I'll look into getting these setup. > # Anyway, I'll join you in irc to look over what you doing..... Sorry -- when you messaged me in there, I was just getting off a big 14 hour international flight. I've got a long layover now, and probably I'll be in IRC again if you want to pop in there. Though, I'm quite exhausted and might collapse on some airport benches... > Then by all means follow the existing latest code. Well that was my question. Should I follow (A) or (B)? IPsec does (B); everything else does (A). Does IPsec have a security reason for doing (B)? Is there some denial of service attack that can be mounted, or some information disclosure, or some sort of oracle attack? Or is (A) pretty much clearly better and more robust under abuse, and IPsec is just behind the times? Probably I shoul djust read the ECN RFCs to actually understand what all this is doing and make up my mind. > Postel is long dead, and the internet is a far more hostile place. > so did cake manage to successfully ratelimit the output to 10Mbit's in > this configuration? It did. With I rate limited the actual link to 10mbps, and iperf3 got around 9mbps over TCP, which seems about right considering TCP and considering the packet encapsulation overhead. > > cake's stats also show marks and drops. (tc -s qdisc show dev lo) Seems to work: qdisc cake 8008: root refcnt 2 bandwidth 10Mbit diffserv4 flows rtt 100.0ms raw Sent 82329355 bytes 95473 pkt (dropped 5295, overlimits 195966 requeues 0) backlog 137124b 150p requeues 0 memory used: 502566b of 500000b capacity estimate: 10Mbit Tin 0 Tin 1 Tin 2 Tin 3 thresh 10Mbit 9375Kbit 7500Kbit 2500Kbit target 78.7ms 83.9ms 104.9ms 314.6ms interval 173.7ms 178.9ms 209.8ms 629.3ms Pk-delay 0us 93.9ms 0us 0us Av-delay 0us 91.2ms 0us 0us Sp-delay 0us 83.8ms 0us 0us pkts 0 100916 2 0 bytes 0 84254676 318 0 way-inds 0 0 0 0 way-miss 0 1 1 0 way-cols 0 0 0 0 drops 0 5295 0 0 marks 0 4660 0 0 Sp-flows 0 0 0 0 Bk-flows 0 1 0 0 last-len 65536 0 0 0 max-len 0 1494 187 0 > acks do not get ECN marks. I'll need to think carefully about the infoleak aspects of allowing ECN. It seems nearly as bad as the DSCP infoleak. Is this information that's okay to be sent in the clear? I'm not quite sure yet. > (I note that mosh is also ecn enabled, last I looked) Cool. I recall when they added the DSCP priority, but I don't recall ECN. I'll try that out. I'm a big Mosh user -- and the roaming feature of WireGuard was inspired by it. > I will. I got very busy today getting a "final" version of the > fq_codel code for ath9k wifi tested. It's lovely. :) If you are into > openwrt, we've got builds available at: > > https://lists.bufferbloat.net/pipermail/make-wifi-fast/2016-August/000940.html > > and patches due out tomorrow. It would be great fun to also start > fiddling with wireguard with this new stuff. I think the right thing - > now that you've found it - is to ape what the newer protocols do... > (and someone shoul fix linux ipsec) Excellent. I've just arrived in the mountains for a week and a half with my family, so I have limited access to hardware, but I am very interested in OpenWRT and WireGuard performance. Baptiste, a OpenWRT developer, hangs out on this mailing list and got a WireGuard package in LEDE which is quite cool. That's excellent about a faster ath9k driver. ^ permalink raw reply [flat|nested] 12+ messages in thread
* Re: [WireGuard] fq, ecn, etc with wireguard 2016-08-29 17:16 ` Jason A. Donenfeld 2016-08-29 19:23 ` Jason A. Donenfeld @ 2016-08-30 0:24 ` Dave Taht 1 sibling, 0 replies; 12+ messages in thread From: Dave Taht @ 2016-08-30 0:24 UTC (permalink / raw) To: Jason A. Donenfeld; +Cc: WireGuard mailing list :whew: On Mon, Aug 29, 2016 at 10:16 AM, Jason A. Donenfeld <Jason@zx2c4.com> wrot= e: > Hey Dave, > > You're exactly the sort of person I've been hoping would appear during th= e > last several months. The bufferbloat project has had a lot of people randomly show up at the party to make a contribution, getting a little PR in the right places always helps. Glad to have shown up, am sorry to be so scattered today and not reviewing detailed code. >> A) does wireguard handle ecn encapsulation/decapsulation? >> >> https://tools.ietf.org/html/draft-ietf-tsvwg-ecn-encap-guidelines-07 >> >> Doing ecn "right" through vpn with a bottleneck router with a fq_codel >> enabled qdisc allows for zero induced packet loss and good congestion >> control. > > At the moment I don't do anything special with DSCP or ECN. I set a high > priority DSCP for the handshake messages, but for the actual transport > packets, I leave it at zero: > > https://git.zx2c4.com/WireGuard/tree/src/send.c#n137 > > This has been a TODO item for quite some time; it's on wireguard.io/roadm= ap > too. The reason I've left it at zero, thus far, is that I didn't want to > infoleak anything about the underlying data. Is there a case to be made, > however, that ECN doesn't leak data like DSCP does, and so I'd be okay ju= st > copying those top bits? I'll read the IETF draft you sent and see if I ca= n > come up with something. It does have an important utility; you're right. The ietf consensus was that a 2 bit covert channel wasn't useful and that being able to expose congestion control information was ok. >> B) I see that "noqueue" is the default qdisc for wireguard. What is >> the maximum outstanding queue depth held internally? How is it >> configured? I imagine it is a strict fifo queue, and that wireguard >> bottlenecks on the crypto step and drops on reads... eventually. >> Managing the queue length looks to be helpful especially in the >> openwrt/lede case. >> >> (we have managed to successfully apply something fq_codel-like within >> the mac80211 layer, see various blog entries of mine and the ongoing >> work on the make-wifi-fast mailing list) >> >> So managing the inbound queue for wireguard well, to hold induced >> latencies down to bare minimums when going from 1Gbit to XMbit, and >> it's bottlenecked on wireguard, rather than an external router, is on >> my mind. Got a pretty nice hammer in the fq_codel code, not sure why >> you have noqueue as the default. > > There are a couple reasons. Originally I used multiqueue and had a separa= te > subqueue for each peer. I then abused starting and stopping these subqueu= es as > the various peers negotiated handshakes. This worked, but it was quite > limiting for a number of reasons, leading me to ultimately switch to noqu= eue. > > Using noqueue gives me a couple benefits. First, packet transmission call= s my > xmit function directly, which means I can trivially check for routing loo= ps > using dev_recursion_level(). Second, it allows me to return things like > `-ENOKEY` from the xmit function, which gets directly passed up to usersp= ace, > giving more interesting error messages than ICMP handles (though I also > support ICMP). But the main reason is because it fits the current queuing > design of WireGuard. I'll explain: > > A WireGuard device has multiple peers. Either there's an active session f= or a > peer, in which case the packet can be encrypted and sent, or there isn't,= in > which case it's queued up until a session is established. If a peer doesn= 't > have a session, after queuing up that packet, the session handshake occur= s, > and immediately following, the queue is released and the packet is sent. = This > has the effect of making WireGuard appear "stateless" to userspace. The > administrator set up all the peer details, and then typed `ping peer`, an= d > then it just worked. Where did the connection happen? That's what happens > behind scenes in WireGuard. So each peer has its own queue. I limit each = queue > to 1024 packets, somewhat arbitrarily. As the queue exceeds 1024, the old= est > packets are dropped first. OK, well, 1024 packets is quite a lot. Assuming TSO is in use, running at 10Mbit for the sake of example, that's a worst case latency of ~85 *seconds* at that speed, and 98,304,000 bytes of buffering. Even 1024 packets is a lot at a gbit, when TSO/GRO are in use, 850ms. Devices that use soft GRO can also accumulate up to 64K packets, although the spec is 24k, several devices violate it. Thankfully TSO and GRO are not always invoked and that our use of fq, tends to start reducing the maximally sized burst at the endpoints to reasonable values - like 2 superpackets. But, even if you only have 1024 normal sized packets, that's a worst case delay of 1.5 seconds... Now, there is no "right number" for buffering, but various rules of thumb. What we like about the new AQM designs (codel and pie) is that they try to establish a minimal "standing queue", measured in time (which is a proxy for bytes), not packets - 5ms in the case of codel, 16 in the case of pie. and they do it dynamically, based on induced latency. A typical figure for codel's standing queue at 10 mbit is *2* full size packets, moderated a bit by whatever BQL sets, which is 2-3k bytes. There's several great papers/presentations on codel in acm queue, and I'm pretty fond of Van's, my and stephen hemmingers talks on the subject, linked to off of here: https://www.bufferbloat.net/projects/cerowrt/wiki/Bloat-videos/ Anyway, having a shared queue for all peers would more more sensible, and limiting it by bytes rather than packets (as cake does), helpful. Trying to come up with a better initial estimate for how big the queue should be based on what outgoing interfaces are available (e.g. is a gigE interface available? 10GigE), and then be moderated by the aqm. > > There's another hitch: Linux supports "super packets" for GSO. Essentiall= y, > the kernel will hand off a massive TCP packet -- 65k -- to the device dri= ver, > if requested, expecting the device driver to then segment this into MTU-s= ized > bites. This was designed for hardware that has built-in TCP segmentation = and > such. I found it was very performant to do the same with WireGuard. The r= eason > is that everytime a final encrypted packet is transmitted, it has to trav= erse > the big complicated Linux networking stack. In order to reduce cache miss= es, I > prefer to transmit a bunch of packets at once. Well, we also break up superpackets in cake, but we do it with the express intent of allowing other flows through. Staying with my 10Mbit example, a single 64k superpacket would 54ms to transmit, which blows the jitter budget on a competing voip call. I'm painfully aware that this costs cpu, but having shorter queues in the first place helps, and we have experimented with breaking up superpackets less based on the workload and bandwidth, in cake, but haven't settled on a scheme to do so. > Please read this LKML post > where I detail this a bit more (Ctrl+F for "It makes use of a few tricks"= ), > and then return to this email: > > http://lkml.iu.edu/hypermail/linux/kernel/1606.3/02833.html > > The next thing is that I support parallel encryption, which means encrypt= ing > these bundles of packets is asynchronous. All packets in the broken up superpacket are handed to be encrypted in parallel? cool. Can I encourage you to try the rrul test and think about encrypting different flows in parallel also? :) real network traffic, particularly over a network to network oriented vpn is *never* a single bulk flow. > All these requirements would lead you to think that this is all super > complicated and horrible, but I actually managed to put this together in = a > decently simple way. There's the queuing algorithm all together: > https://git.zx2c4.com/WireGuard/tree/src/device.c#n101 > > 1. user sends a packet. xmit() in device.c is called. > 2. look up to which peer we're sending this packet. > 3. if we have >1024 packets in that peer's queue, remove the oldest ones. More than 200 is really a crazy number for a fixed length fifo at 1gbit or = less. > 4. segment the super packet into normal MTU-sized packets, and queue thos= e > up. note that this may allow the queue to temporarily exceed 1024 pack= ets, > which is fine. > 5. try to encrypt&send the entire queue. > > There's what step 5 looks like, found in packet_send_queue() in send.c: > https://git.zx2c4.com/WireGuard/tree/src/send.c#n159 > > 1. immediately empty the entire queue, putting it into a local temp queue= . > 2. if the queue is empty, return. if the queue only has one packet that's > less than or equal to 256 bytes, don't parallelize it. > 3. for each packet in the queue, send it off to the asynchronous encrypti= on > a. if that returns '-ENOKEY', it means we don't have a valid session, = so > we should initiate one, and then do (b) too. > b. if that returns '-ENOKEY' or '-EBUSY' (workqueue is at kernel limit= ), > we put that packet and all the ones after it from the local queue b= ack > into the peer's queue. > c. if we fail for any other reason, we drop that packet, and then keep > processing the rest of the queue. > 4. we tell userspace "ok! sent!" > 5. when the packets that were successfully submitted finish encrypting > (asynchronously), we transmit the encrypted packets in a tight loop > to reduce cache misses in the networking stack. > > That's it! It's pretty basic. I do wonder if this has some problems, and = if > you have some suggestions on how to improve it, or what to replace it wit= h. > I'm open to all suggestions here. Well the idea of fq_codel is to break things up into 1024 different flows. The code base is now generalized so that it can be used by the fq_codel qdisc and the new stuff for mac80211. But! The concept of those flows is still serialized in the end in this codebase, you need to keep pulling stuff out of it until you are done... using merely the idea of fq_codel and explicitly parallizing enqueuing would let you defer nexthop lookup and handle multiple flows in parallel on multiple cpus. > One thing, for example, that I haven't yet worked out is better schedulin= g for > submitting packets to different threads for encryption. Right now I just = evenly > distribute them, one by one, and then wait until they're finished. Clearl= y > better performance could be achieved by chunking them somehow. Better crypto performance, not network performance. :) The war between bulking up stuff to save cpu and breaking things back down again into packets so packet theory actually works, is ongoing. >> C) One flaw of fq_codel , is that multiplexing multiple outbound flows >> over a single connection endpoint degrades that aggregate flow to >> codel's behavior, and the vpn "flow" competes evenly with all other >> flows. A classic pure aqm solution would be more fair to vpn >> encapsulated flows than fq_codel is. >> >> An answer to that would be to expose "fq" properties to the underlying >> vpn protocol. For example, being able to specify an endpoint >> identifier of 2001:db8:1234::1/118:udp_port would allow for a one to >> one mapping for external fq_codel queues to internal vpn queues, and >> thus vpn traffic would compete equally with non-vpn traffic at the >> router. While this does expose more per flow information, the >> corresponding decrease for e2e latency under load, especially for >> "sparse" flows, like voip and dns, strikes me as a potential major win >> (and one way to use up a bunch of ipv6 addresses in a good cause). >> Doing that "right" however probably involves negotiating perfect >> forward secrecy for a ton of mostly idle channels (with a separate >> seqno base for each), (but I could live with merely having a /123 on >> the task) > > Do you mean to suggest that there be a separate wireguard session for eac= h > 4-tuple? Sorta. Instead, you can share a IV seqno among these these queues so long as your replay protection buffer is big enough relative to the buffering and RTT, no need to negotiate a separate connection for each. Then you are semi-serializing the seqno access/increment, but that's not a big issue. There are issues with hole punching on this, regardless, and I wasn't suggesting even trying for ipv4! But we have a deployment window for ipv6 where we could have fun using up tons of addresses for a noble purpose (0 latency for sparse flows!), and routing a set of 1024 addresses into a vpn's endpoint design is possible with your architecture. Linode gives me a 4096 to play with - comcast, a /60 or /56.... Have you seen the mosh-multipath paper?, which sort of ties into your design as well, except that as you are creating a routable device, makes listening on a ton of ip addresses a snap.... https://arxiv.org/pdf/1502.02402.pdf >> C1) (does the current codebase work with ipv6?) > > Yes, very well, out of the box, from day 1. You can do v6-in-v6, v4-in-v4= , > v4-in-v6, and v6-in-v4. I tried to get it going yesterday, ipv6 to ipv6, but failed with 4 tx errors on one side and 3 on the other, reported by ifconfig, no error messages. I'll try harder once I come down from fixing up the fq_codel wifi code.... >> D) my end goal would be to somehow replicate the meshy characteristics >> of tinc, and choosing good paths through multiple potential >> connections, leveraging source specific routing and another layer 3 >> routing protocol like babel, but I do grok that doing that right would >> take a ton more work... > > That'd be great. I'm trying to find a chance to sit down with the fella b= ehind > Babel one of these days. I'd love to get these working well together. Juliusz hangs out on #babel on freenode, paris time. batman-adv is also a good choice, and bmx7 has some nice characteristics. I'm mostly familiar with babel - can you carry ipv6 link layer multicast? (if not, we've been nagging julius to add a unicast only mode) One common use case for babel IS to manage a set of gre tunnels, for which wireguard could be a drop in replacement for. You set up 30 tunnels to everywhere that can all route to everywhere, and let babel figure out the right one. It should be reasonably robust in the face of nuclear holocost, a zombie invasion, or the upcoming US election. https://tools.ietf.org/html/draft-jonglez-babel-rtt-extension-01 BTW: To what extent would source specific routing help solve your oif issue? https://arxiv.org/pdf/1403.0445.pdf we use that extensively to do things that we used to do with policy routing, and it's a snap to use... and nearly all device's we've played with are built with IPv6 subtrees. but it's an ipv6 only feature, getting that into ipv4 would be nice. > >> Anyway, I'll go off and read some more docs and code to see if I can >> answer a few of these questions myself. I am impressed by what little >> I understand so far. > > Great! Let me know what you find. Feel free to find me in IRC (zx2c4 in > #wireguard on freenode) if you'd like to chat about this all in realtime. > > Regards, > Jason --=20 Dave T=C3=A4ht Let's go make home routers and wifi faster! With better software! http://blog.cerowrt.org ^ permalink raw reply [flat|nested] 12+ messages in thread
end of thread, other threads:[~2016-08-30 0:18 UTC | newest] Thread overview: 12+ messages (download: mbox.gz / follow: Atom feed) -- links below jump to the message on this page -- 2016-08-27 21:03 [WireGuard] fq, ecn, etc with wireguard Dave Taht 2016-08-27 21:33 ` jens 2016-08-27 22:03 ` Dave Taht 2016-08-29 17:16 ` Jason A. Donenfeld 2016-08-29 19:23 ` Jason A. Donenfeld 2016-08-29 19:50 ` Dave Taht 2016-08-29 20:15 ` Dave Taht 2016-08-29 21:00 ` Jason A. Donenfeld 2016-08-29 21:11 ` Dave Taht 2016-08-29 23:24 ` Dave Taht 2016-08-29 23:57 ` Jason A. Donenfeld 2016-08-30 0:24 ` Dave Taht
This is a public inbox, see mirroring instructions for how to clone and mirror all data and code used for this inbox; as well as URLs for NNTP newsgroup(s).
{kind=link}
{kind=link}